|
|
|
|
Обработка данных |
|
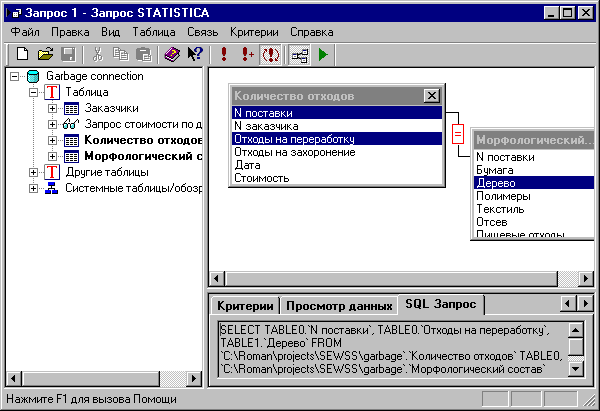
STATISTICA предоставляет удобные средства получения данных из хранилищ данных. Мы рассмотрим STATISTICA Query и In-place Database Processing (IDP). STATISTICA QueryТермин Query в переводе с английского означает запрос. Применительно к базам данным запросы для пользователя представляются в виде критериев, по которым будет сделана выборка из базы данных. Язык запросов универсальный - SQL, т.е. язык структурированных запросов. Взаимодействие клиента и сервера баз данных происходит по принципу клиент-сервер. На сервер баз данных STATISTICA Query отсылает запрос с помощью технологий ODBC или OLE DB (о них мы поговорим чуть попозже), СУБД (система управления баз данных) получает запрос и начинает поиск данных, которые удовлетворяют критерию запроса, и после отсылает данные обратно клиенту. Мы рассмотрим два стандарта, предложенных компанией Microsoft, это ODBC и OLE DB. Начнем с первого. ODBC (Open DataBase Connectivity) - это набор соглашений, предложенных компанией Microsoft, которые позволяют получить доступ к информации из широкого круга баз данных (например, MS Access, Oracle или даже на платформе UNIX) и формирование запросов с помощью SQL. OLE DB (Object Linking and Embedding Database) - это набор соглашений, предложенных также компанией Microsoft, которые позволяют получить доступ к информации из широкого круга баз данных. OLE DB - это архитектура баз данных, которая обеспечивает универсальную интеграцию данных по всей сети компании, от сервера до рабочей станции, независимо от типа данных. Это более обобщенная и более эффективная стратегия доступа к данным, чем ODBC, так как она основана на технологии Component Object Model (COM) и поддерживает больше различных типов данных. STATISTICA Query может работать с обоими типами драйверов. Теперь перейдем к главному окну этого инструмента:
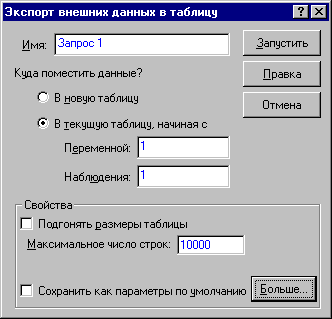
В левой части окна находятся таблицы базы данных, к которой мы подключились. Теперь можно выбрать таблицу и перенести ее в правую часть окна двойным щелчком мыши. Правая часть главного окна служит для визуального построения запроса, т.е. там находится графическое представление запроса. В нижней части окна находятся панели, с помощью которых можно отслеживать все изменения в запросе. Например, в панели Последовательность полей находятся поля, которые используются в запросе; панель Критерии - находится список всех критериев запроса; Просмотр данных - показана часть результатов выполнения запроса; SQL Запрос - исходный текст запроса SQL. После того, как вы построили запрос, открывайте меню Файл - Вернуть данные в STATISTICA. Появится окно, в котором нужно указать, куда будут записываться результаты запросов.
В этом окне можно выбрать ячейку в таблице, начиная с которой будут записываться данные. Но проще всего выбрать опцию В новую таблицу. Теперь можно нажать на кнопку Запустить.
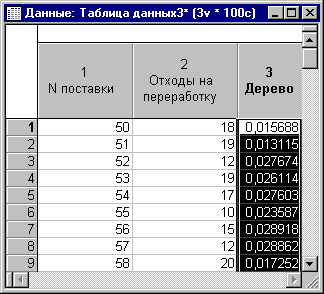
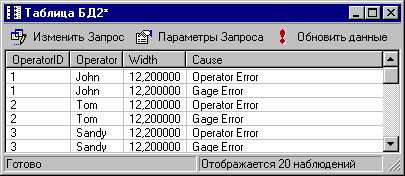
Так выглядит результат запроса в таблице STATISTICA. Если данные базы данных периодически изменяются, то таблицу STATISTICA можно обновить командой из меню Файл - Внешние данные - Обновить данные. После рассмотрения базовых возможностей STATISTICA по работе с запросами, перейдем к IDP. Обработка баз данных на местеТехнику построения запросов мы рассмотрели в предыдущем параграфе. Казалось бы все просто, нужно построить запрос и в дальнейшем работать с результатами этого запроса. Но если объем данных очень велик? Например, результаты запроса могут потребовать больше свободного места на диске компьютера, чем имеется в наличии. Физическое увеличение дисковой памяти компьютера приведет в удорожанию стоимости всего проекта, к тому же если аналитик может редко работать с такими объемами данных. Из программных решений можно выделить следующее, на компьютер будет закачиваться не весь запрос, а только его часть. Причем, после того, как первая часть обработана, закачивается следующая и так, пока не будут обработаны все данные. Это и есть суть технологии In-Place Database Processing (в переводе Обработка баз данных на месте), в дальнейшем мы будем использовать принятую в STATISTICA аббревиатуру IDP. IDP - это по сути прямой метод доступа к базе данных, который позволяет существенно ускорить работу с данными для однопроходных анализов. Теперь посмотрим, как это делается в STATISTICA. Для этого выберите в меню Файл - Создать, далее выберите вкладку Интерфейс БД и нажмите ОК.
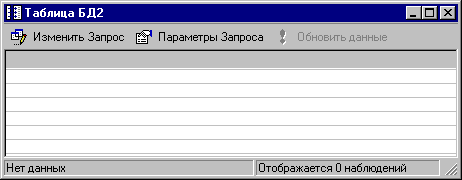
Теперь нажмите кнопку Изменить запрос, на экране появится окно STATISTICA Query. Проделайте все необходимые шаги, описанные в предыдущем параграфе, посвященном STATISITCA Query. Запустите запрос, перед вами появится следующее окно:
Если у вас не получилось, то попробуйте использовать более новые версии драйверов, например, Microsoft OLE DB Jet 4.0. Анализы могут работать с этой таблицей как с обычной таблицей STATISTICA. По мере необходимости IDP просто будет заменять существующуе данные на новые. При работе с IDP вы встретитесь с термином курсор. Курсор - это структура данных, которая хранит результаты запроса. Тип курсора определяет доступные функциональные возможности. Некоторые курсоры позволяют продвигаться вперед по результатам вашего запроса, другие позволяют вам продвигаться как вперед, так и в обратном направлении. Обработка баз данных на месте (IDP) поддерживает поступательный и статический (т.е. произвольного доступа) курсоры.
|