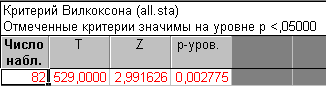|
|
|
|
Часть2: Анализ анкет в STATISTICA |
|
После того, как мы отсканировали анкеты, записали результаты в базу данных и научились извлекать эти данные в STATISTICA, можно перейти к следующему этапу: анализу данных, в чем собственно и заключалась цель анкетирования. Первоначальный анализ данных анкет можно проводить в модуле :
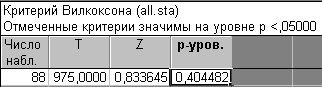
Рассмотрим третий пункт (Корреляции). Это относится к так называевым ранговым корреляциям. Например, в анкете есть вопрос, где просят выставить оценку запаху и цвету какого-либо продукту, это и есть ранги. Далее, чтобы узнать насколько зависят друг от друга эти оценки, необходимо вычислить . Как трактовать полученный коэффициент корреляции? Во-первых коэффициент корреляций должен быть значим, в этом случае он будет выделен в результирующей таблице красным цветом. Далее мы смотрим на его значение, чем его значение по модулю ближе к единице, тем больше линейная взаимосвязь между ними. Вновь обратимся к . После корреляций стоит четыре пункта сравнения групп. Например, при проведении внутреннего панельного исследования сравнивались два разных сорта, при этом каждым участником была выставлена общая оценка для каждого сорта. И теперь нам нужно сравнить эти оценки. Можно конечно вычислить средние или медианы для каждого сорта вина и просто сравнить их, но в этом случае мы не учтем разброс (дисперсию) оценок. Проведем этот анализ с помощью Непараметрической статистики. У нас две зависимых переменных (2 сорта вина), поэтому выбираем пункт Сравнение двух зависимых переменных. Далее нажимаем кнопку Переменные и в появившемся диалоге в левом списке выбираем переменную с оценками для 1 сорта вина, в правом для 2го сорта вина, нажимаем ОК. Нажимаем на кнопку Критерий Вилкоксона. Появляется таблица с результатами:
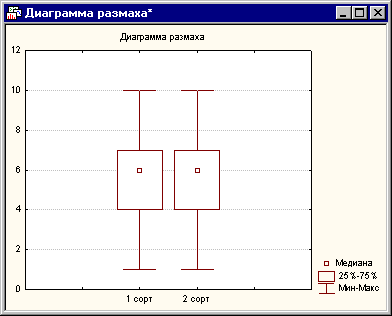
Во-первых запись в таблице не выделена красным цветом, во-вторых значение p-уровня равно 0.4, что намного больше значения 0.05. Следовательно критерий нам говорит, что группы не различаются, т.е. общие оценки равны. Чтобы разобраться с этой ситуацией построим диаграмму размаха:
Маленькие квадраты в центре обозначают средние оценки, большие квадраты - границы верхнего и нижнего процентилей. Как мы видим из графика оценки практически полностью совпали, что согласуется с выводами критерия. Теперь рассмотрим исследование двух других сортов вина. Результаты:
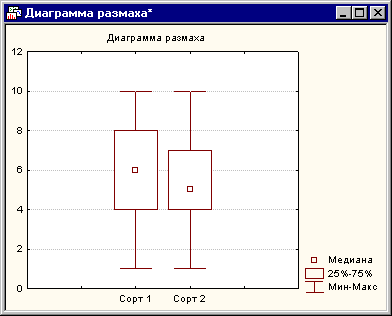
Строка в таблице выделена красным цветом, значение p-уровня равно 0.0027, что намного меньше значения 0.05. Отсюда можно сделать вывод, что согласно критерию Вилкоксона оценки для этих сортов вин отличаются друг от друга. Обратимся теперь к диаграмме размаха:
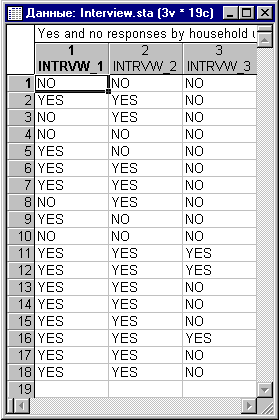
На диаграмме размаха видно, что оценки для второго сорта были более низкие, чем для второго. Что касается пункта Сравнение нескольких независимых групп, то его применение аналогично разобранному, только он применяется, когда вы хотите сравнить более двух переменных, например, три сорта вин. В непараметрической статистике также представляет интерес Q критерий Кохрена. Он позволяет сравнивать более двух групп зависимых выборок, которые могут принимать только два значения (например, Да или Нет). Например вы проводите анкетирование одной группы людей осенью, зимой и летом, и вам нужно знать, изменились ли результаты опроса с течением времени. Рассмотрим следующий пример. Положим, вы интересуетесь эффектом, какое влияние оказывает стиль интервьюера на число респондентов, согласившихся дать ответы на деликатные вопросы в очном опросе. Заметим, что всегда трудно получить ответы на такие деликатные вопросы, как, например, финансовое положение или здоровье в таких опросах, и возможно, вы захотите выяснить, повышает или нет, стиль задания вопросов интенсивность ответов (т.е. уменьшается ли количество отказавшихся отвечать). Для этой цели, можно научить интервьюера проводить интервью в одном из следующих стилей (1) восторженно, дружелюбно и заинтересовано (Interview 1), (2) очень сдержанно и формально (Interview 2), (3) беспристрастно и резко (Interview 3). Затем вы могли бы выбрать 18 троек семей, которые были ранее осторожны в своих ответах, и случайным образом приписать три семейства в каждом наборе к одному из трех стилей, в каком с ними будет проводиться интервью. Зависимая переменная определяет удачу (1-Да - 1-Yes) или неудачу интервью (0-Нет - 0-No). Данные этого примера находятся в файле Interview.sta, входящий в комплект стандартных примеров, который устанавливается вместе со STATISTICA:
В стартовой панели выбираем все переменные:
Нажимаем кнопку ОК. Тогда появится таблица результатов:
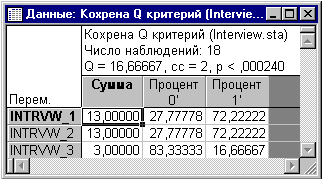
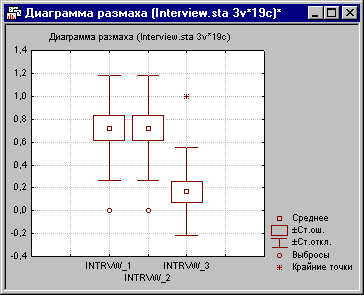
Сразу обращаем внимание на уровень значимости в таблице p=0,00024, это говорит нам о том, что группы отличаются друг от друга. Самая правая колонка показывает процент семей, которые раскрыли свою личную информацию (Процент 1). Интересно отметить, что не обнаружено различия в эффективности между первым стилем: восторженно, дружелюбно и заинтересованно (переменная Intrvw_1) и вторым: (2) очень сдержанно и формально (Intrvw_2), таким образом, выражение интереса интервьюером, кажется, не имеет значения. Однако число отказавшихся отвечать увеличилось, когда использовалось интервью третьего типа: беспристрастно и резко (Intrvw_3). А теперь построим диаграмму размаха для иллюстрации:
Как вы можете заметить, этот график очень хорошо согласуется с аналитическими результатами. Все изложенные выше методы анализа это всего лишь 1% возможностей STATISTICA в анализе данных. Для более глубокого анкетного анализа в STATISTICA существует большое число методов. Например, в дальнейших анкетных опросах вы хотите добавить новые вопросы и убрать лишние, в этом вам поможет .
|